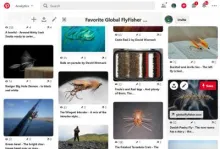
The blocks of nicely laid out images on GFF has required quite a bit of work to refine.
Nerd alert
This is NOT about fly fishing or fly tying, but about site development and nerdy stuff.
Many years ago, in 2006, I bumped into a great and inspiring article written by Harvey Kane on the renowned web developer and web designer site A List Apart.
Back when I read the article, I thought it would be a great technique to use. It breaks up the usual way of presenting images on the web. The norm is simple thumbs shown individually or regular grids (in reality HTML tables) of thumbs. Another common way is the simple, larg wall-to-wall images, simply filling the page from edge to edge. Sometimes it's clickable, sometimes not. This is higly favored these days, because it's easy to adapt to mobile presentation. The magazine layout creates a more fluid layout and also a more varying layout, which is rarely seen online, but quite commonly seen on print, like in books or magazines.
Some sites, like Google Photos, present images in a magazine layout like style, but essentially just adjust and crop all images to a certain height, and crop their individual width to fit the page width when arranged in rows.
The magazine system can do better than that. It can put one portrait image to the right and two landscape images to the left, and simply scale them all to create a rectangular block.
I added it to a small photo site that I ran. Since this site was custom built, adapting the original script wasn't that hard. I simply worked on folders and took the images from a given folder and laid them out using the magazine image system, merged the HTML with the page template, et viola!


Quite brilliant
The system is quite brilliant. Using fairly simple logic and a number of "scenarios", the code will calculate a way of scaling and arranging a number of images, filling out a rectangle and spacing them out evenly. Even though the logic might be simple, it's still requires about 600 lines of code to create the layout itself including a lot of repetitive patterns, growing in number as the count and combination of landscape/portrait images change and grow. I haven't done much to the original code, but added some logic needed to integrate it into other systems. I also wanted to make the images clickable, so that users could click on to larger version, another addition to the original script.
There are limitations to the magazine system, which mainly have to do with the number of images. Since all scenarios – number and orientation of images – are essentially hard coded into the system, the system breaks once you try to combine too many pictures. I usually stay below 6 images, and then it works.

Adding it to GFF
I thought it would also be a great addition to GFF. I had already implemented an image system, which offered automatic scaling of the images and could set them up in simple grids, showing clickable thumb prints and doing most of the household automatically.
Adding the magazine image layout system wasn't quite as trivial here.
Kane supplied a pretty complete example in the article, but adapting that to the custom system that GFF used back then, required quite a lot of work. Since the example used a fairly simple system of file names and GFF worked with image information stored in a database, I needed a middle layer between Kane's code and my own. I also needed a simple way of adding the images to the article text, so that I could inject magazine blocks in any position in any text using a simple tag system.
It took some fiddling and a lot of experiments, but in the end I could enter a custom <gff magazine ... /> "pseudo-HTML" tag in the text, and GFF's CMS would interpret that into the HTML needed to form the block.
So a code something like
would be interpreted by the magazine system into a left floated block, 800 pixels wide containing the images with id's 1, 2, 3 and 4 in the database. The caption under the images would be "Some nice images". I would not have to worry about size or sequence, portrait or landscape. The system would take care of that.
The drawback is of course that I need to add the codes manually to the text and that there's no WYSIWYG preview of the text with images. I have no problems with that, but many end users would of course not be able to use such a crude system, so I haven't rolled this out to any clients.
Scaling
One thing that made it a challenge was scaling the images. When presenting a version of an image online, you want a physical copy of the image in the right size. You do not want the original file, and then let the browser scale it. This will download images way too large, and be a waste of bandwidth and browser resources.
I used a small PHP-script originally provided by Kane to do the job on the fly. It would read the original image, scale it in memory and simply output the image directly to the browser as as a JPG-stream, never saving the image to a file.
Since more and more images were shown using the magazine image system and more and more people were visiting the site, this script ran constantly, and soon executing this single PHP-snippet was eating up so much processor time that the site was shut down by the host several times for using too many resources.
So I had to save the images on the disk, and serve them from there in stead of creating them dynamically. This was one of the first steps of many in an effort to serve static content to most users rather than creating it for every visit.
The system ran for many years, and the load on the server with the image cache was minimal.
The move to Drupal
Then I moved GFF to Drupal, and basically all custom made code had to be converted into proper Drupal modules, including the magazine image system.
I had already developed the module in connection with moving my photography site to Drupal, but implementing it on GFF meant another round of optimization because of the fairly high load on this site.
GFF is already heavily cached using the Boost module as described in an earlier article. But the problem with the magazine images remained the same as before: the images needed to be scaled to all kinds of strange sizes, and that had to be done in such a way that the already scaled images were saved to disk and read from there rather than created every time.
Drupal's way of interpreting text (in Drupal called text filtering) is also different from what I had used before, so a new interpreter for the codes had to be made in the form of a Drupal filter. I didn't want to change the tag code, because the tags were embedded in thousands of articles on the site, which I didn't want to edit. So the tag pattern remains the same today.
As a final layer of caching, I started caching the finished HTML for the magazine image blocks so that both the HTML and the image files were simply static files on the server and could be fetched really quickly.
Single images
When Drupal usually shows images, it uses "image styles", a core feature, which allows the system to scale, save and efficiently cache images in predetermined sizes. The thing is that the magazine image system uses individual sizes for almost every single image.
If I want to present images in 200, 300, 400, 500, 550, 600, 850 and 1200 pixels, I need an image style for each of these sizes. If I then at one point need 700 pixels, I have to create that image style before being able to use it.
With the magazine system I simply make a magazine block 700 pixels wide, which will then spark the creation of a static copy of the image in that size.
The sequence
So building a page that shows magazine images now goes like this:
- First .htaccess code makes the server look for a Boost-cached page.
- If that isn't found or is too old Drupal looks for a node cache.
- If that isn't found or is too old Drupal builds the node.
- This is done by reading the node details in the database and building the HTML.
- When the system encounters a magazine block tag in the text, it looks for a cache of that block.
- Each block has a fingerprint, which is used as a unique identifier of the block – actually just the block code MD5'ed.
- If a file with that id isn't found or is too old, my magazine module builds the code and saves it to a file.
- In that process the image sizes are calculated.
- The magazine module looks for the scaled image files.
- If an image isn't found the module creates it and writes it to disk.
- The mosule builds the HTML containing links to the static image files.
- The magazine HTML is written ti the magazine cache.
- The magazine HTML is then merged into to the HTML of the proper field in node.
- Drupal caches the node and builds the page.
- Boost caches the page, ready to be served at the next visit.
- Drupal serves the page to the web server
- The web server serves the page to the user.
The next time a user requests that same page, it's essentially only the first and last steps that run. All HTML and images have been generated and saved as files, and are fetched from the file system on the server, which is a very low resource process and usually very fast.

Cache in many levels
So the process is quite elaborate as you can see, with cache in several of the steps, but today the system runs smoothly with very little overhead and basically no redundancy. In essence this takes a few seconds if the whole process has to be run. Once the page has been formed, it can be served from cache in a split second.
The magazine block cache as well as the scaled images are essentially eternal. Since a new combination of images and sizes will give a new id, the system will create a new cache file for that combo. The old one is basically kept for always, since it's just a small HTML file that takes up very few resources.
The same thing goes for the images. Once a scaled image has been generated, it's kept. Images are named with the size in their filename, so that they can be found easily when needed, and once scaled, they also just stick around for ever, ready to be fetched by the browser. I still use my version of Kane's little image.php script, but this now does very little work, since 99.9% of the images have already been created, and just need to be located and served as files, which is blitz fast on almost any server.
Administration
There's a bit of administration needed for the system, like a way to actually destroy the cache for individual blocks. I rarely need to delete the images, and when I do, I simply locate the image and delete it using FTP.
Apart from that, the system doesn't require much maintenance, and has basically run untouched for years now, and is almost used in all articles on this site.
- Log in to post comments